What is Resiliency? How do you make systems resilient?
What is Redundancy? How do you introduce redundancy in systems?
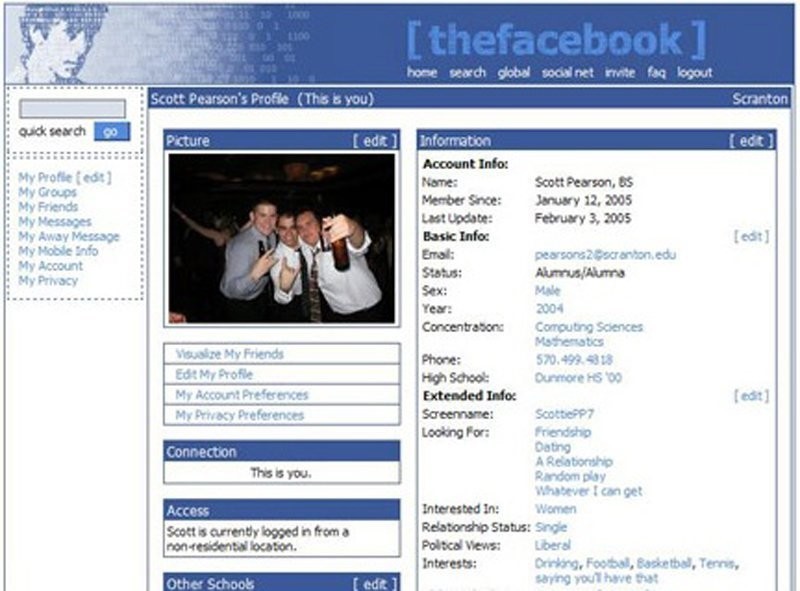
Mark is a 19-year old Harvard student. He has created a simple website ‘Thefacebook’.
Thefacebook offers the creation of a new profile where you can upload a photo, share your
interests, and connect with other people.
Currently, he has this website running on his localhost and database on his own computer.
Scaling for 10,000 Req/s users:
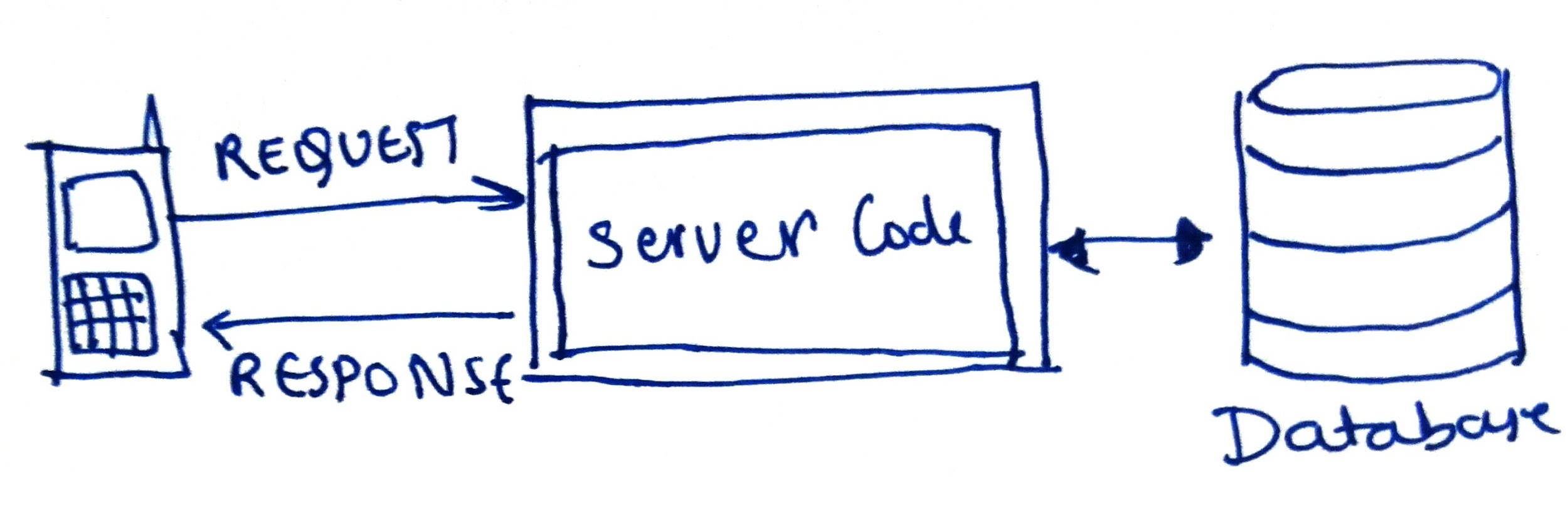
Now he decides to launch this website for Harvard college students. He buys a domain
thefacebook.com and creates an API. Hence when a Harvard student types thefacebook.com, a
request is sent to the college server, and they get a response on their own device. Currently,
he is paying for one server that has 8GB RAM and 100GB memory.
Learn: How does DNS work? Watch this 6 min video.
Scaling from 10,000 Req/s users to 1L Req/s user:
Thefacebook is getting really popular in college. The user base has increased such that the
server is receiving about 1L requests/sec. Users start complaining that the system takes
more time to generate a response. Why so?
Learn: How many simultaneous connections can a single server handle? What does it depend on?
According to
this discussion, Each connection has some required memory associated with it to
maintain the connection. That memory may only be a KB or even less per person, or it could
be many MB, depending on the type of request.
If you are talking Internet Protocol version 4 (IPv4) connections (the normal Internet
connection in the world today between clients and servers) the protocol itself has only 16
bits for the port number, so only 65,535 connections of any TCP/IP or UDP/IP type can exist
simultaneously on a single computer.
Mark doesn’t want to lose his user base because of the degrading performance. He buys more RAM
and Memory. He has now 128GB RAM and 500GB of hard disk and now even he has brought a new
processor.
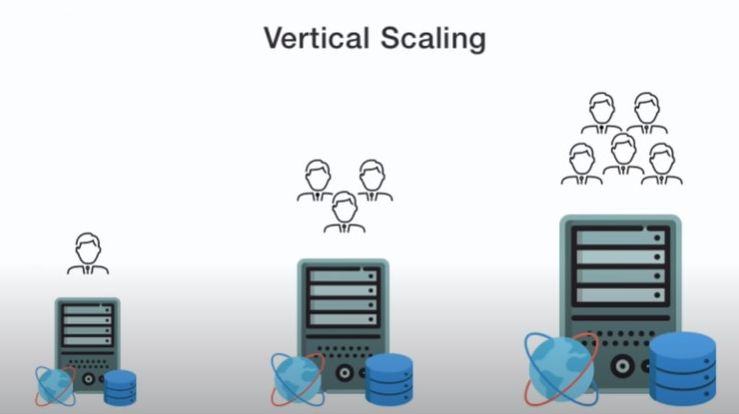
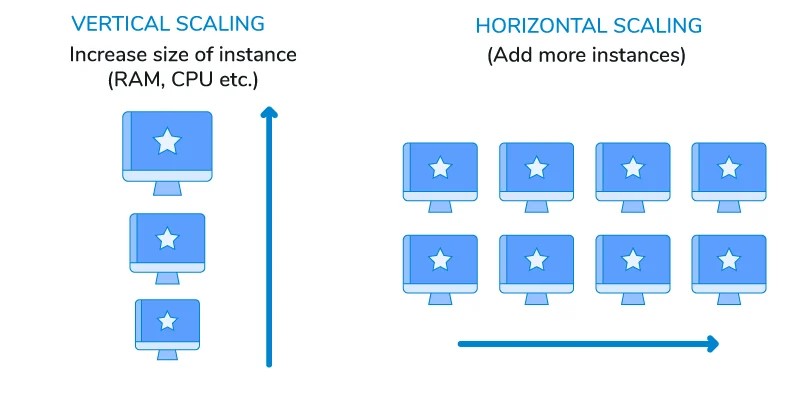
Learn: What Mark just did is he got a bigger machine. We can handle more requests by
throwing more money at the problem. When you are buying a bigger machine it means your
computer is going to be larger and therefore it can process the request faster. This is
called ‘Vertical Scaling’. That is you are scaling your computer vertically and making it
bigger and bigger.
Scaling from 1L Req/sec to 1M Req/sec:
Mark's users are rapidly increasing and now mark knows that his users are about to reach
1 million. His server will again soon become insufficient in handling a million requests. Mark says, ‘Ok, I
will buy more RAM and more Memory!, but how long can I keep doing the same
thing?’ Although he has got money to get a bigger server, there is still a limit up to which
he can scale up his server.
One of his friends just walks in his room and was just about to trip over the server power
cable. Thankfully, he managed to balance himself.
Hush!!! Mark is in a big problem now. If anyone trips over the power cable, all the system shuts
down in a fraction of second. He recognizes it is a single point of failure.
Learn: Single Point of Failure
A single point of failure (SPOF) is a part of a system that, if it fails, will stop the
entire system from working.
‘Rather than getting a few or really good one big machine, why don't I get a bunch of cheaper
machines? Each of maybe 8GB RAM and 100GB Memory. This way there would be no single point of
failure as well as I can get as many servers as I want!!’
Soon Mark gets 20 such servers to handle a million requests.
( 1 server can handle 65,535 simultaneous connections~ min 60k connections, to handle. Therefore
to handle 1M connection he would need almost 16 such servers. Mark is very confident about the
popularity of his website. So he got 20 such servers :D)
Learn: Horizontal Scaling
When you scale by adding more machines into your pool of resources, it is called Horizontal
Scaling.
By scaling this way, he ensured that if after a few years even if his user base starts to
decrease, he can just sell the extra servers. But Mark’s future is different! His website is
amazing and it is going to attract more and more users. So he can also keep on adding more
servers whenever he feels the need of adding more servers! Even if any server fails, another
server can take the charge. Now there is no single point of failure. This way he has
introduced Resiliency.
Learn: Resiliency
System resilience is an ability of the system to withstand a major disruption and to recover
within an acceptable time. If one server crashes, another server in the pool can start to
serve traffic. There is no single point of failure.